哈囉大家~我們今天把最後的損失跟優化函數講完。這章節聽完的讀者,不一定要侷限RL,學到的知識也可以放在其他影像辨識專案上,官網提供了些範例程式碼,有空就去晃晃吧~傳送門
損失函數是神經網路定義要收斂的對象函數。因為龐大的參數節點,可以擬合任意函數,我們可以不用知道權重跟bias的值明確要設多少,但可以靠反向傳播做梯度下降,讓函數逐步收斂,直到逼近最低點(global minimum)。這裡我們用均方差,差值做平方,加總再除於總樣本數量。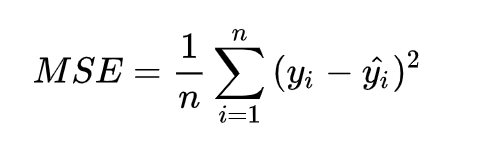
無法把loss明確定義,那就等於無法擬合函數,實際的loss function設計要看你想做什麼事情,以前筆者做OCR檢測,其中的損失函數有摻雜機率學理論,至於其他的損失函數則可參考 https://keras.io/losses/#usage-of-loss-functions ,但讀者也不需要看到公式就嚇得趕緊關掉電腦,馬上躲進棉被裡,很多損失函數很直覺的(和藹的),例如剛介紹的均方差,以及視覺辨識常用到的IOU(https://www.pyimagesearch.com/2016/11/07/intersection-over-union-iou-for-object-detection/)。
這邊做補充,我們之前介紹的q估計跟q現實就是裡面y值跟y-hat值,兩個差異最小化,就是我們期望能收斂的Q-function。
網路模型在學習的時候會有α值叫學習率,它是負責控制梯度的收斂程度,如果單次更新α值過高,收斂方向的速度就會變快,你說越快不是越好嗎?不一定,梯度下降的收斂過程就像走小山丘,太大會暴衝會不穩,太小收斂會太慢,或是卡在局部解(local minimum)而跨不出來了。為了讓α更smart,就會採取像Adam的優化函數來控制α。
讀者可先了解概念跟重要參數,對於底層不理解一開始不用太糾結。由淺至深慢慢學習,對於概念懂了就會想懂原理,原理了解會想手算,手算完如果能舉一反三會更有成就感。身旁或許沒有大牛(像李弘毅老師),不過筆者推薦NNDesign,原理介紹很清楚還搭配紮實的課堂練習。好哩今天介紹到這,大家明天見拉~

